
Tech Topic | February 2019 Hearing Review
A review of the rationale for and enhanced features in AutoSense OS 3.0 with binaural signal processing, and how the new system is designed to achieve the most appropriate settings for the wearer, optimizing hearing performance in all listening environments, including media streaming.
It can be challenging to hear, understand, and actively engage in conversation in today’s fast-paced and “acoustically dynamic” world, especially for a listener with hearing loss. The Phonak automatic program has been designed to adapt seamlessly, based on the acoustic characteristics of the present environment and the benefit for clients.
AutoSense OS™ 3.0 is the enhanced automatic operating system in Phonak Marvel™ hearing aids. It has been optimized to recognize additional sound environments for even more precise classification, applying dual path compression, vent loss compensation, and a new first-fit algorithm. In combination, these new enhancements to the Phonak automatic classification system ensure that the listener gains access to speech clarity and quality of sound irrespective of the environment, enabling them to actively participate in everyday life.
Optimal sound quality in every listening environment for listeners with hearing loss is always the goal of hearing aid manufacturers and hearing care professionals alike. As pointed out by MarkeTrak, “Hearing well in a variety of listening situations is rated as highly important to hearing aid wearers and has a direct impact on the satisfaction of hearing aid use throughout daily tasks and listening environments.”1
Without conscious effort, humans naturally classify audio signals throughout each day. For example, we recognize a voice on the telephone, or tell the difference between a telephone ring versus a doorbell ring. For the most part, this type of classification task does not pose a significant challenge; however, problems may arise when the sound is soft, when there is competing noise, or when the sounds are very similar in acoustical nature. Of course, these tasks become even more difficult in the presence of a hearing loss, and hence, great strides have been made in hearing instrument technology to incorporate classification capabilities within the automatic program.
Technology Evolution
In previous years, the sound processing of hearing aids was limited to a single amplification setting used for all situations. However, since the soundscape around us is dynamic—with frequent acoustical changes in the environment—it is unrealistic for a hearing aid with only one amplification setting to deliver maximum benefit in every environment. The evolution of hearing aids has seen the introduction of sound-cleaning features, such as noise cancellation, dereverberation, wind noise suppression, feedback cancellation, and directionality. These features offer maximum benefit to overall sound quality and speech intelligibility when they are appropriately applied, based on analysis of the sound environment.
Rather than having these sound-cleaning features permanently activated, their impact is greatest when they are applied selectively. For example, a wearer may not hear oncoming traffic if noise cancellation is permanently suppressing sound from all directions. Thus, defaults are set in the system for different environments.
Of course, the possibility exists to add manual programs to accommodate acoustic characteristics of specific listening environments (eg, an “everyday” program with an omnidirectional microphone enabled and a “noise” program with a directional microphone enabled). However, having several manual programs increases the complexity for the hearing aid wearer. Research data shows the increasing preference of wearers for automatically adaptive sound settings over manual programs for different environments,2 and this is further confirmed by data-logging statistics which reveal a decline in manually added programs with the launch of newer technology platforms (Figure 1).3
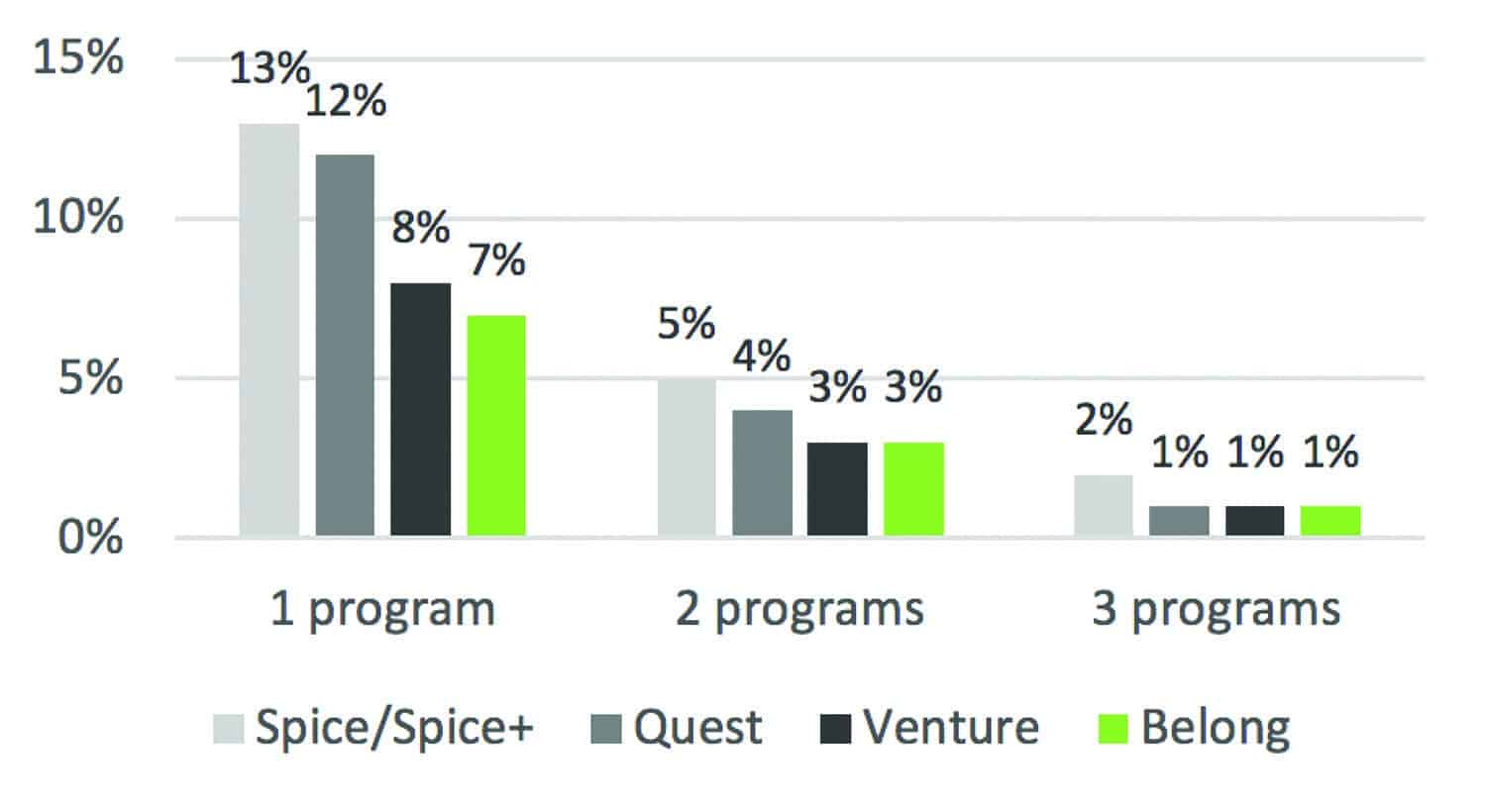
Figure 1. Market research data from Phonak in 2017: Percentage of fittings with manual programs at 2nd session across hearing aid platforms Spice/Spice+, Quest, Venture, and Belong (n = 183,331).
Results of studies focusing specifically on speech intelligibility demonstrate that the majority of participants achieve a 20% improvement in speech understanding while listening in AutoSense OS than in a “preferred” manual program across a wide variety of listening environments, suggesting that manual programs may not always be appropriately or accurately selected.4 Even more interesting is the fact that users rate sound quality as being equal between the automatic and manual programs.5 According to this same research from Searchfield et al,5 a possible explanation may be that the practical application of selection relies on the wearer’s manual dexterity, normal cognition, noticeable benefit, and motivation levels. Furthermore, their research confirms a bias towards selection of the first program in the setup—whether or not this would be considered “audiologically” optimal.
Having an automatic program which can seamlessly adjust to select the most appropriate settings in any environment therefore saves both the client and the hearing care professional effort, time, and hassle.
First-generation AutoSense OS™
When Phonak AutoSense OS was originally developed, data from several sound scenes was recorded and used to “train” the system to identify acoustic characteristics and patterns. These characteristics include level differences, estimated signal-to-noise ratios (SNRs), and synchrony of temporal onsets across frequency bands, as well as amplitude and spectrum information. Probabilities of the degree of match between “trained” versus “identified” acoustic parameters in real time are then calculated for the most optimal selection of sound settings in each environment. There are seven sound classes: Calm Situation, Speech in Noise, Speech in Loud Noise, Speech in Car, Comfort in Noise, Comfort in Echo, and Music. Three of the programs—Speech in Loud Noise, Music, and Speech in Car—are considered “exclusive classes” (ie, stand-alone) while the other four programs can be activated as a blend when it is not possible to define complex, real-world environments by one acoustic classification. For example, Comfort in Echo and Calm Situation can be blended with respect to how much each of these classifications are detected in the environment.
Enhanced Benefits for Wearers
With AutoSense OS 3.0, Phonak has gone a step further and incorporated data from even more sound scenes for the classes Calm Situation, Speech in Noise, and Noise into the training for additional system robustness. Enabling the desired signal processing is the goal of automatic classification, so to support the wearer’s understanding in speech-in- noise situations, the program Speech in Noise is activated even earlier than before.
AutoSense OS 3.0 is the foundation for steering the signal processing and applying the most appropriate setting for the wearer based on the acoustics present in the environment. Refinements to the audiological settings within this are always sought to further enhance the user experience, and the improvements occur in different areas of the signal processing.
In order to maintain the natural modulations of speech in noise as well as streamed media, dual path compression is available and activated based on the listening environment. This allows temporal and spectral cues in speech to be more easily identified and used by the wearer.6
It is known that a full and rich sound is preferred by wearers while streaming audio, so the system enhances the sound quality of streamed audio signals by increasing the vent loss gain compensation. The result is an increase in low-frequency gain by up to 35 dB, which is especially beneficial to overcome the vent loss of a receiver-in-canal (RIC) hearing aid, most likely to be fitted with an open coupling (depending on the hearing loss and/or client comfort). This low-frequency “boost” is applied to streamed signals (or any other alternative input source, including a telecoil), while inputs received directly to the hearing aid microphones remain uncompromised, maintaining the frequency response of a Calm situation.
The Adaptive Phonak Digital (APD) algorithm has also been enhanced for spontaneous first-fit acceptance. The gain for first-time wearers fitted to an adaptation level of 80% has been softened for frequencies above 3000 Hz to reduce reported shrillness, but without compromising speech intelligibility. The desired effect of this is that the wearer experiences a comfortable and clear sound quality from the outset.7
New Classification of Media Signals
Listening to music and enjoying it is achieved by an alternate setting that is used to attain optimal speech understanding. In an internal study conducted at the Phonak Audiology Research Center (PARC), participants emphasized their preferences for clarity of speech for dialogue-dominated sound samples and sound quality for music-dominated samples (C Jones, unpublished data, “Preferred settings for varying streaming media types,” 2017). This preference applies not only in the acoustic environment where signals reach the hearing instrument microphones directly, but also for streamed media inputs via the Phonak TV Connector or Bluetooth connection to a mobile device.
Phonak Audéo Marvel with AutoSense OS 3.0 now incorporates streamed inputs into the automatic classification process offering the wearer speech clarity as well as an optimal music experience. A recent study conducted at DELTA SenseLab in Denmark confirmed that the new Audéo Marvel, in combination with the TV Connector, is rated by wearers as close to their defined ideal profile of sound attributes for streamed media across a range of samples including, speech, speech in noise, music, and sport (Figure 2). The Audéo Marvel streaming solution was also rated among the top streaming solutions across 7 competitor solutions.8 This confirms that the way in which the classifier now categorizes streamed media into the sound classes “Speech” versus “Music” is yet another way in which the system provides ideal hearing performance for wearers in their everyday lives.

Figure 2. Sound attributes plot for Ideal profile (in gray) & AutoSense OS 3.0 in Phonak Audéo Marvel with TV Connector (in green).
Binaural VoiceStream Technology
The Binaural VoiceStream Technology™ has been reintroduced within AutoSense OS 3.0. This technology facilitates binaural signal processing, such as binaural beamforming, and enables programs and features such as Speech in Loud Noise (when StereoZoom™ is activated), Speech in 360°, and DuoPhone. StereoZoom uses 4 wirelessly connected microphones to create a narrow beam towards the front, for access to speech in especially loud background noise. We know that the ability to stream the full audio bandwidth in real time and bidirectionally across both ears improves speech understanding and reduces listening effort in challenging listening situations.9 This reduction in listening effort, and consequently, memory effort, has been demonstrated in recent studies employing electrophysiological measures, such as electroencephalography (EEG), where significantly reduced Alpha-wave brain activity is noted when listening with StereoZoom compared to listening with more open approaches of directionality.10 When we consider this in terms of the “Limited Resources Theory” described in psychology by Kahneman11(ie, that the brain operates on a limited number of neural resources), it highlights that efficiencies in sensory processing, through use of such advanced signal processing, may serve to free up resources to benefit higher cognitive processing for the wearer.
Taking this a step further to look into behavioral patterns of speakers and listeners with hearing loss in a typical group communication scenario in the real world, methods such as video and communication analyses have been used effectively. Changes in behavior when listening with StereoZoom versus traditional fixed directional technologies have been compared and correlated with subjective ratings of listening effort. StereoZoom has been shown to increase communication participation by 15%, and decrease listening effort by 15% relative to the fixed directional condition.12
Summary
The ability of a hearing instrument to offer acceptable “hands-free” listening by automatically adapting to multiple situations increases the adoption rate of the instrument.1 The enhanced AutoSense OS 3.0, with binaural signal processing, achieves this by selecting the most appropriate settings for the wearer, optimizing hearing performance in all listening environments, and now during media streaming, too. The wearer is freed from expending energy on effortful listening and can focus their enjoyment instead on tasks which are more meaningful to them, confident in the knowledge that their hearing instruments will automatically take care of the rest.

Correspondence can be addressed to Tania Rodrigues at: [email protected]
Citation for this article: Rodrigues T. A new enhanced operating system in Phonak hearing aids: AutoSense OS 3.0. Hearing Review. 2019;26(2)[Feb]:22-26.
References
-
Kochkin S. MarkeTrak VIII: Consumer satisfaction with hearing aids is slowly increasing. Hear Jour. 2010;63(1):19-32.
-
Rakita L; Phonak. AutoSense OS: Hearing well in every listening environment has never been easier. https://www.phonakpro.com/content/dam/phonakpro/gc_hq/en/resources/evidence/white_paper/documents/insight_btb_autosense-os_belong_s3_028-1585.pdf Published August 2016.
-
Überlacker E, Tchorz J, Latzel M. Automatic classification of acoustic situation versus manual selection. Hörakustik. 2015.
-
Rakita L, Jones C. Performance and preference of an automatic hearing aid system in real-world listening environments. Hearing Review. 2015;22(12):28-34.
-
Searchfield GD, Linford T, Kobayashi K, Crowhen D, Latzel M. The performance of an automatic acoustic-based program classifier compared to hearing aid users’ manual selection of listening programs. Int J Audiol. 2017;57(3):201-212.
-
Gatehouse S, Naylor G, Elberling C. Linear and nonlinear hearing aid fittings-1.Patterns of benefit. Int J Audiol. 2006;45(3):130–152.
-
Jansen S, Woodward J; Phonak. Love at first sound: The new Phonak precalculation. https://www.phonakpro.com/content/dam/phonakpro/gc_hq/en/resources/evidence/white_paper/documents/insight_btb_marvel_precalculation_season4_2018_028-1931.pdf. Published July 2018.
-
Legarth S, Latzel M; Phonak. Benchmark evaluation of hearing aid media streamers. DELTA SenseLab, Force Technology. www.phonakpro.com/evidence
-
Winneke A, Appell J, De Vos M, et al. Reduction of listening effort with binaural algorithms in hearing aids: An EEG study. Poster presented at: The 43rd Annual Scientific and Technology Conference of the American Auditory Society; March 3-5, 2016; Scottsdale, AZ.
-
Winneke A, Latzel M, Appleton-Huber J; Phonak. Less listening- and memory effort in noisy situations with StereoZoom. https://www.phonakpro.com/content/dam/phonakpro/gc_hq/en/resources/evidence/field_studies/documents/fsn_stereozoom_eeg_less_listening_effort.pdf. Published July 2018.
-
Kahneman D. Attention and Effort.Englewood Cliffs, NJ: Prentice-Hall, Inc;1973.
-
Schulte M, Meis M, Krüger M, Latzel M, Appleton-Huber J; Phonak. Significant increase in the amount of social interaction when using StereoZoom. https://www.phonakpro.com/content/dam/phonakpro/gc_hq/en/resources/evidence/field_studies/documents/fsn_increased_social_interaction_stereozoom_gb.pdf. Published September 2018.



